Caso de estudio
Benchmarking de la experiencia de usuario
Comparando dos conceptos del Learn Path en Fretello con SUM, la métrica única de usabilidad.

Lideré: Plan de test, prototipos (ProtoPie), guiones de tareas, análisis de datos, la decisión sobre el diseño combinado
Por qué usar este método
Dos diseños, los dos se ven bien, ninguno gana de forma obvia. Ese es el momento de dejar de discutir sobre capturas de pantalla y empezar a medir.
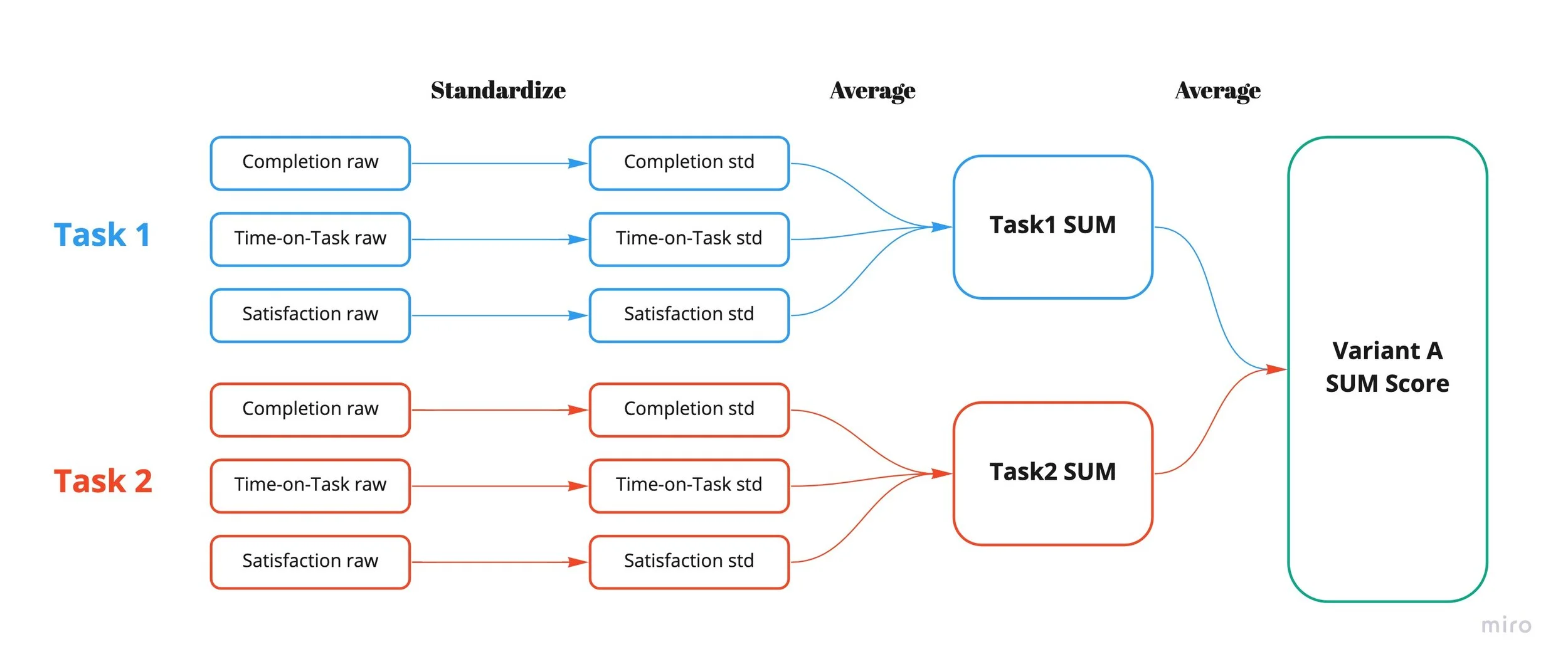
SUM (la métrica única de usabilidad) es una puntuación estandarizada que combina las tres cosas que de verdad te importan en un test de usabilidad: si la gente terminó la tarea (efectividad), cuánto tardaron (eficiencia) y cómo se sintieron al hacerlo (satisfacción). Un número por variante. Discute sobre el número, no sobre cuál mockup se ve más pulido.
La razón por la que recurro a esto antes que a un test A/B es la independencia respecto a ingeniería. No necesitas build, ni feature flag, ni cohorte de rollout. Un prototipo clicable, un guion de tareas y un cronómetro bastan para empezar a medir.
Los conceptos en competencia
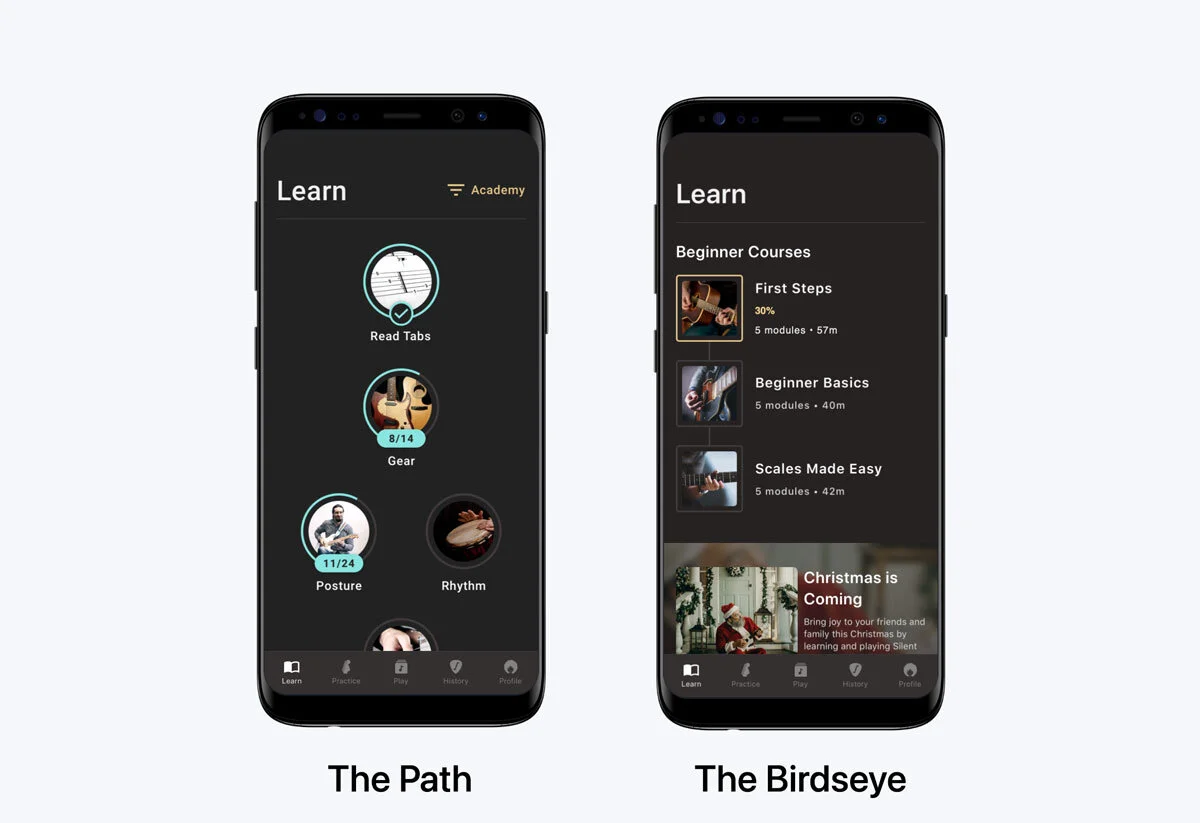
En Fretello, el workshop del Learn Path (el que describo en el caso de estudio de Fretello) produjo dos prototipos. Los dos clicables en ProtoPie. El mismo contenido por debajo, modelos mentales distintos por encima.
- Variante A, The Path. Una escalera guiada. Los principiantes retoman donde lo dejaron; el siguiente módulo siempre es el evidente.
- Variante B, The Birdseye. Un catálogo de cursos con el progreso superpuesto. Ves todo el panorama y decides.
Análisis de usabilidad
Escribimos un guion de tareas que mapeaba a los requisitos: completar un módulo, navegar al siguiente módulo, encontrar un curso destacado, retomar donde lo dejaste, saltar a una lección concreta. Tres rondas de testing en dos sprints. Cada tarea capturaba finalización, tiempo en tarea y satisfacción autorreportada; estandarizamos las puntuaciones brutas y las promediamos en un SUM por variante.
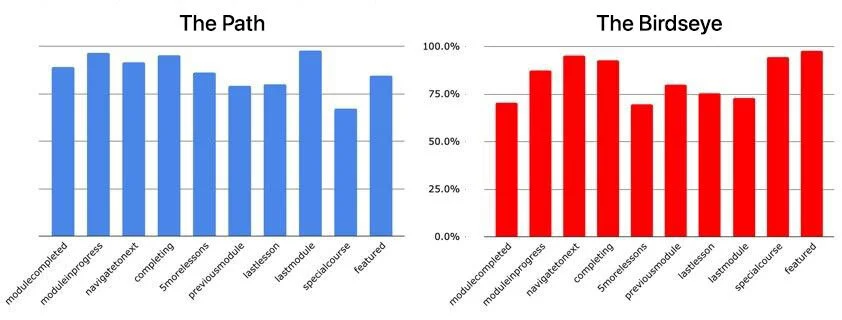
Ganó The Path. SUM medio entre tareas: 91,5%, margen de error 11%. Pero The Birdseye no estaba acabado. En unas tareas concretas (buscar un curso destacado, encontrar una lección que no habían hecho antes) The Birdseye estaba ganando.
Combinando los conceptos
Tras discutirlo dentro del equipo de UX, lanzamos un tercer prototipo que cogía la columna vertebral de The Path y le atornillaba la affordance de catálogo de The Birdseye. Dos entradas al mismo contenido: la escalera guiada para principiantes, el catálogo para exploradores.
El prototipo combinado puntuó por encima del 75% de SUM en cada tarea principal. Se acabó el bache en las tareas que favorecían a The Birdseye. Trabajamos con ingeniería para especificarlo, lanzamos el MVP a producción y los números cuadraron:
- Retención de la primera semana: +35%. Los principiantes que instalaban la app aguantaban lo suficiente para llegar al curso tres.
- Conversión trial-to-paid: +20%. La gente que se quedaba enganchada tenía más probabilidades de convertir.
La lección, obvia con la perspectiva del tiempo: cuando dos prototipos puntúan bien, la respuesta correcta a menudo no es elegir uno. Es preguntarte qué hace bien cada uno y si puedes tener los dos sin confundir al usuario.

Por qué vuelvo a esto una y otra vez
Dos razones.
SUM es la evidencia objetiva más barata que puedes conseguir.Si tu equipo está dividido entre dos diseños, pon los prototipos delante de usuarios y deja que ellos rompan el empate. La conversación después del test es radicalmente distinta a la de antes: ya no es “creo que A es mejor”, sino “los usuarios terminaron la tarea 3 una quinta parte más rápido en B”.
Encaja limpiamente con el hypothesis-driven design.Tu hipótesis nombra lo que esperas que sea cierto; SUM te dice si lo era. Las métricas que mides (finalización, tiempo, satisfacción) tienen la misma forma que la línea “Sabremos que esto es cierto cuando…”.
¿Atascado entre dos diseños, o viendo cómo se fuga la retención sin causa obvia?
Albot, mi clon en bot, está a un clic. Puede contarte cómo corro benchmarks como este, cuándo SUM es la herramienta adecuada y si encajo con lo que buscas. O simplemente saluda.
Other case studies
- The SellerCrowd contribution engine3x MRR, 65x monthly contributions, zero new headcount.
- Bringing Fretello to WWDC19On Apple's keynote stage as a Sign in with Apple launch partner.
- The GVC cashier redesign4x average deposit value, second-deposit rate from 2% to 8%, time-to-success cut from 20s to under 6s.
- Building in 2026The chatbot, scorer, and digest that run this portfolio.
- Hypothesis-driven designAligning a team around tested beliefs instead of stacks of documentation.