Case study
Hypothesis-driven design
Aligning a product team around tested beliefs, not stacks of documentation.

Owned: Workshop facilitation, hypothesis writing, validation method choice, post-test synthesis
What a hypothesis actually is
A design hypothesis is an assumption someone on the team thinks is true. The founder, the PM, the most senior IC, or the new hire who just shadowed five users. The author doesn't matter. What matters is whether you've put it under a test that ties to something measurable.
The point of writing it down is to make the belief checkable. After that, you can find out whether you actually understand your users, or whether you've been pattern-matching on yourself.
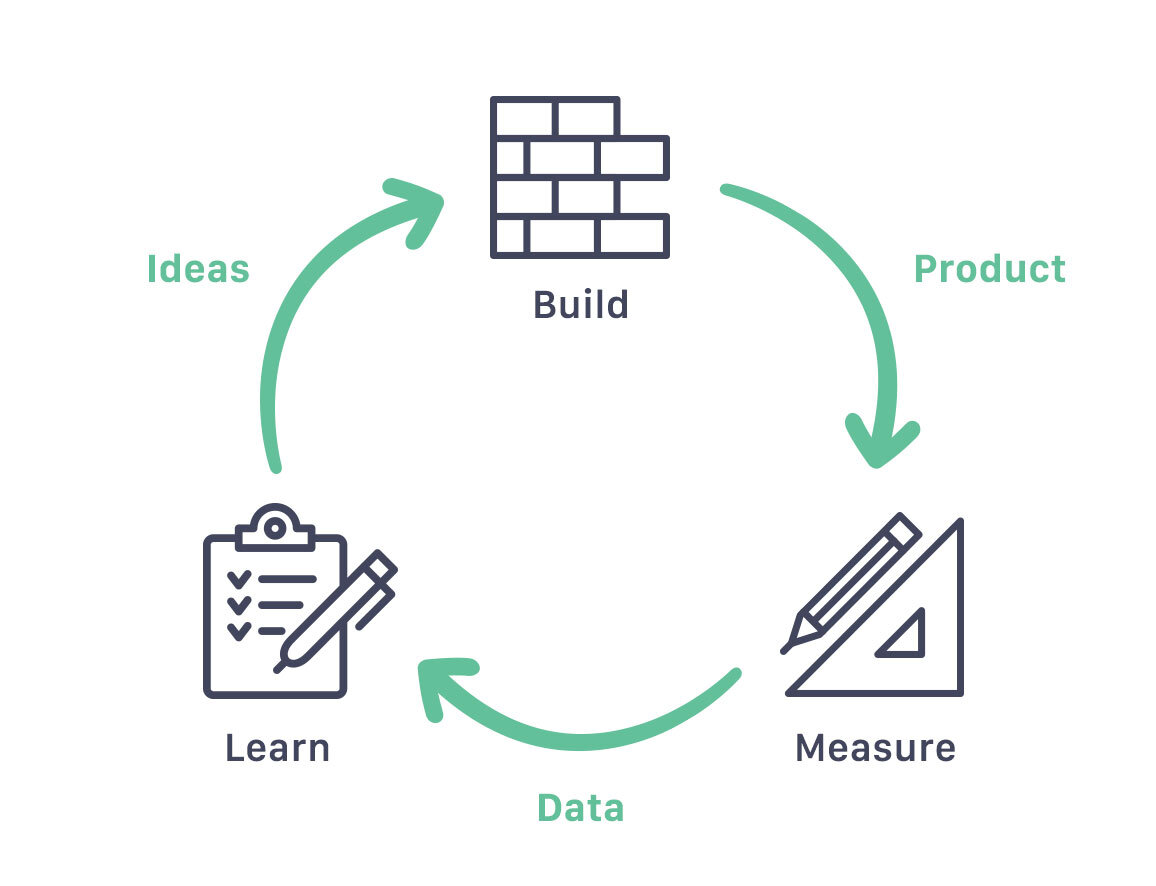
Every test that comes back with an answer (confirming or refuting) opens up the next set of questions. That's the loop. The only discipline is to base each hypothesis on something you've seen, in user behaviour or in the data, rather than on what you'd like to be true.
![Annotated hypothesis template: 'We believe that… [Assumption]', 'For… [Persona]', 'We will… [UX Outcome]', 'We'll know this is true when… [Metrics]'. Each placeholder is highlighted with a marker swipe.](/case-studies/hdd/hypothesis-anatomy.jpg)
Better collaboration, less documentation
Hypothesis-driven design changed how the teams I worked with showed up to work. Anyone could propose a hypothesis. Anyone could push back on someone else's. The PM, the engineer, the visual designer, the QA lead, all in the same room with the same shape of statement on the wall.
When the format is short and shared, the conversation is about evidence, not about who's allowed to have an opinion. That alone reduces the amount of internal documentation a team needs. You don't write a fifteen- page brief to align on a feature. You write four lines, agree on the metric, and ship a test.

How to write your hypothesis
Four lines. Same shape every time:
We believe that… [the assumption]
For… [the persona or segment]
We will… [the change in user behaviour we're betting on]
We'll know this is true when… [the metric]
When we redesigned the iOS notifications prompt at Fretello, the goal was to lift opt-in rate so beginners would actually stick to a routine. The hypothesis came out like this:
We believe that by exposing the value proposition of reminders,
for beginner guitar players,
we will help them build the practice routine they need to succeed at learning,
we'll know this is true when the opt-in rate to notifications has increased by X%.
That's it. Four lines on the wall. Now we can argue about each line on its own (is the persona right? is X% the right bar? does “value proposition” mean what we think it means?) and disagreements stay specific instead of philosophical.
Validating your hypothesis
Pick the validation method before you run anything. Quantitative (A/B, opt-in deltas, retention curves) tells you what changed. Qualitative (interviews, walkthroughs, watching someone in front of the screen) tells you why.
Decide upfront. Otherwise the team will quietly redefine “success” once results land. I've watched this happen on hypotheses I wrote myself. The fix is to lock the metric and the threshold in the same conversation that locks the hypothesis.
After you've measured, three things can happen:
- The hypothesis was right. Ship the change. The next hypothesis usually writes itself: if reminders work for beginners, do they also work for intermediates? At what frequency?
- The hypothesis was wrong.The interesting part. Now you know one specific thing that isn't true, which is more valuable than another opinion.
- The result was ambiguous.Tighten the experiment, or admit the question wasn't sharp enough to begin with.
Either way, the loop continues.
Why I keep coming back to this
The thing I like about hypothesis-driven design is that it makes a team disagree well. Disagreements about a hypothesis are productive: someone has evidence, someone has a different theory, the experiment is the tiebreaker. Disagreements about features tend to be unproductive: someone has an opinion, someone has a different opinion, the loudest one wins.
I've used this loop at Fretello, at SellerCrowd, and on smaller projects in between. It's portable. It scales down to a single designer-PM pair and up to a cross-functional pod. The hardest part is the discipline of not skipping the metric line because everyone “agrees” already.
Need help framing a hypothesis or running this loop on your team?
Albot, my clone bot, is one click away. He can talk through how I run these workshops, when this approach is the right tool, and whether I'm a fit for what you're after. Or just say hi.
Other case studies
- The SellerCrowd contribution engine3x MRR, 65x monthly contributions, zero new headcount.
- Bringing Fretello to WWDC19On Apple's keynote stage as a Sign in with Apple launch partner.
- The GVC cashier redesign4x average deposit value, second-deposit rate from 2% to 8%, time-to-success cut from 20s to under 6s.
- Building in 2026The chatbot, scorer, and digest that run this portfolio.
- Benchmarking the user experienceComparing two Learn Path concepts at Fretello with SUM. +35% week-one retention.